
=Understanding data characteristics and the requirements for each characteristic is essential in choosing the right cloud storage strategy and deployment model.
This post will help you understand how to best define your data characteristics and requirements as a starting point to implementing a successful data strategy. Let’s have a look at those characteristics and requirements.
Data Characteristics
1. Performance
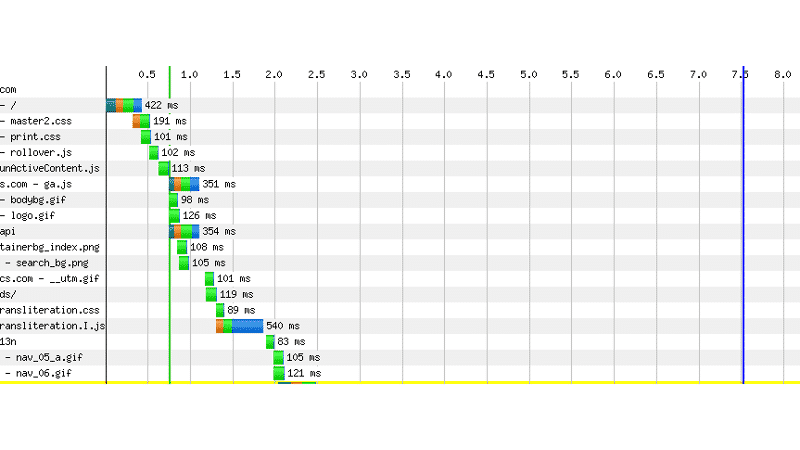
Websites generally aim for half-second response time or less (for more information, visit Importance of Site Speed in Google’s own words). So real time performance (or “sub-second”) response times, and delayed time ranges from a few seconds to batch time frames of daily or weekly.
Response time categories can be very important in decision-making. Here are few strategies for fast performance:
- Using a caching layer
- Reducing the size of data sets (by storing hash values)
- Denormalizing data sets
- Separating databases into read-only and write-only nodes
- Archiving aging data to reduce the size of tables
2. Volume
Volume is the amount of data that a system must maintain. Relational databases are really effective, but they become too slow when volume hits a certain size. Volume also impacts the design of a backup strategy. Backups may consume large amounts of CPU cycles. So we perform full backups daily. While incremental backups could be performed multiple times throughout the day. A good strategy is to perform backups on a slave database.
3. Retention Period
This denotes how long data should be kept. For instance, it a requirement to store financial data for about seven years for auditing purpose. This actually means the data should not be destroyed until it is older than seven years. Data that has to be maintained and that doesn’t have to be available online in real time can be stored on cheap offline disks. We can keep this archived data off-site at a disaster recovery site. Data that needs to be retrieved instantly must be stored on a fast performing disk, which can recover quickly from failures.
4. Tenancy (multi in the cloud)
Multi-tenance means that multiple users (tenants) are sharing the same infrastructure. In case of single-tenancy, an instance of a software application and supporting infrastructure serves only one tenant. Here are two models for multi-tenancy: data isolation and data segregation.
In isolation model, the application takes a multi-tenant approach to the application layer by sharing application servers and so on. The database layer is single-tenant, and this is a sort of hybrid approach between multi-tenancy and single-tenancy. Here we still get the benefits of independence and privacy while reducing some of the cost and complexities. This model protects the privacy of each tenant’s data and to allow tenants to scale independently. At CloudSigma this model is available by leveraging Zadara’s VPSA offering available for our cloud locations.
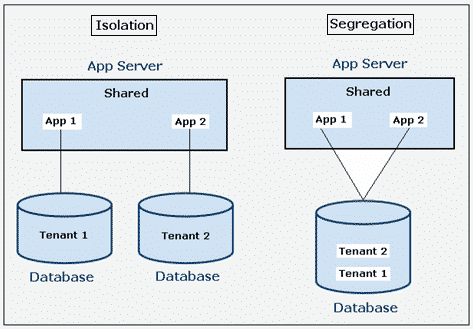
Under a segregation model, all tenants receive access to all layers. This model is the most cost effective because it increases the degree of reusability of system infrastructure. It’s also the least complex and requires much fewer servers but here the challenge is in delivering reliable performance levels to every tenant and avoiding ‘noisy neighbor’ issues. For this reason CloudSigma employs an all-SSD based storage system for it’s mainline compute storage offering which deals much better with random IOPS and multi-tenant environments.
5. Data Store Types
Relational databases are great for online transaction processing (OLTP) activities and for processing ACID (atomicity, consistency, isolation, durability) transactions to ensure data reliability. They also have a powerful querying engine and more security features.
As disk solutions have become cheaper, enterprises have started storing more data than ever before, and such huge amounts of data used to perform analytics, pattern recognition, machine learning and data mining. Enterprises can benefit from cloud services by provisioning many servers to distribute workloads across many nodes in order to speed up the analysis. If data gets big enough, it’s highly difficult for relational databases to perform better and faster.
NoSQL databases have therefore become increasingly popular as a way to resolve these sort of issues. Here a great tutorial on how to set-up and optimize a MongoDB cluster on our cloud servers.
1
There are four types of NoSQL databases: Key-Value Store, Column Store, Document Store and finally Graph Database
(1) Key-Value Store: A key-value store database makes use of a hash table where a unique key with a pointer points to a particular item of the data. This is the simplest of the four types. In fact, it is fast, highly scalable, and useful for processing large amounts of writes just like tweets. The database is also good for viewing static and structured data such as historical orders, events & transactions. Some Key-Value Store database examples include Riak and Voldemort.
(2) Column Store: Column store database can store and process huge amounts of data distributed over many servers. The hash key points to multiple columns organized in column families. Here, we add columns on the fly and they don’t have to exist in every row. This database is scalable, easy to alter, and very useful while integrating data feeds from disparate sources with different structures. Apache’s HBase and Cassandra projects are the most popular Column Store databases.
1
(3) Document Store: A document store database is used for storing unstructured data. Data is often encapsulated in PDF, Word, XML, JSON, Excel and other document types. Most logging solutions use a document store to combine log files from various sources such as database logs and applications server logs. This database is great at scaling large amounts of data in different formats. Popular Document Store databases are MongoDB, OrientDB and Apache CouchDB.
(4) Graph Database: This database is used for storing interconnected relationships. It shows visual representation of relationships, especially in social media analysis. Graph databases include HyperGraphDB, InfiniteGraph and Neo4J.
Note: Other options – The size of audio/video files can range from a few hundreds of megabytes to several gigabytes. Likewise, most latency that users of web services experience results from the front-end. Applications that try to store such large fields may struggle to create a fast performing and great user experience. A good strategy is to use a content delivery network (CDN) in conjunction with an optimised cloud data storage strategy. Also, a CDN is a network of computers located in multiple data centers across the Internet that provides high performance and availability to end users by storing multiple copies of the same content and serving end users the closest copy of that content.
- Can Cloud Computing Enhance Agile Software Development? - June 15, 2015
- Data characteristics to be considered for cloud servers - April 28, 2015